





Table of Contents
What is Data Science, and why should someone pursue a career in Data Science?
Data science is an interdisciplinary field that uses scientific methods, processes, algorithms, and systems to extract meaningful information from data. It combines mathematics, statistics, programming, and domain expertise to extract insights from structured and unstructured data. Data scientists play a critical role in industry decision-making processes by analyzing trends, making predictions, and uncovering hidden patterns. Pursuing a career in data science offers unparalleled opportunities to work on challenging problems, drive innovation, and make a tangible impact on businesses and society. With data becoming the new currency of the digital age, data science professionals are in high demand, making it a rewarding and future-proof career choice.
The key difference between a Data Scientist and a Data Analyst
While data scientists and analysts work with data to extract insights, their roles and responsibilities differ significantly. The key difference is data analysts focus on “what happened” and “why it happened,” while data scientists often address “what will happen” and “how to make it happen.”
- Data Analyst: Focuses on analyzing existing data to identify trends, create reports, and provide actionable insights. They primarily use Excel, SQL, and visualization tools (e.g., Tableau) to support business decision-making.
- Data Scientist: Goes beyond analysis by building predictive models, designing algorithms, and working with unstructured data. They leverage advanced programming skills, machine learning, and statistical methods to solve complex problems and drive innovation.
Skills Required to Become a Data Scientist
Programming Language
A strong command of programming languages like Python or R is fundamental for data science. These languages are used for data manipulation, analysis, and building machine learning models. Python’s vast ecosystem of libraries (e.g., Pandas, NumPy, and Scikit-learn) makes it the most popular choice in the field.
Version control systems like Git are essential for tracking changes in code and collaborating with teams. Platforms like GitHub and GitLab enable data scientists to manage projects efficiently, ensuring reproducibility and collaboration.
Data Structures and Algorithms
Understanding data structures (e.g., arrays, lists, dictionaries) and algorithms (e.g., sorting, searching) is crucial for writing efficient code. These concepts form the backbone of data manipulation and problem-solving in data science.
SQL
Structured Query Language (SQL) is indispensable for querying and managing data stored in relational databases. Data scientists use SQL to retrieve, filter, and analyze large datasets, making it a key skill for working with structured data.
Mathematics, Statistics, and Probability
Mathematics forms the foundation of data science. Key areas include:
- Linear Algebra: Underpins machine learning algorithms and data transformations.
- Statistics: Enables data scientists to understand data distributions, test hypotheses, and conclude.
- Probability: Helps model uncertainty and build predictive models.
Data Handling and Visualization
The ability to clean, preprocess, and visualize data is critical for uncovering insights. Tools and libraries like Pandas, Matplotlib, Seaborn, and Tableau are widely used for these tasks. Visualization helps communicate findings effectively to stakeholders.
Machine Learning
Machine learning involves building models that can learn from data and make predictions. Key concepts include supervised and unsupervised learning and popular algorithms like linear regression, decision trees, and neural networks. Libraries such as Scikit-learn and TensorFlow simplify the implementation of these models.
Deep Learning
Deep learning, a subset of machine learning, uses neural networks with multiple layers to handle complex tasks like image recognition and natural language processing. Frameworks like TensorFlow and PyTorch are commonly used to build and train deep learning models.
Big Data
Big data refers to datasets that are too large or complex for traditional tools to handle. Apache Spark and Hadoop are potent platforms for processing and analyzing big data, allowing data scientists to extract insights from vast amounts of information.
Natural Language Processing (NLP)
NLP focuses on the interaction between computers and human language. It involves tasks like sentiment analysis, text summarization, and machine translation. Libraries like NLTK, SpaCy, and Hugging Face Transformers are widely used in NLP projects.
Data Scientist Roadmap
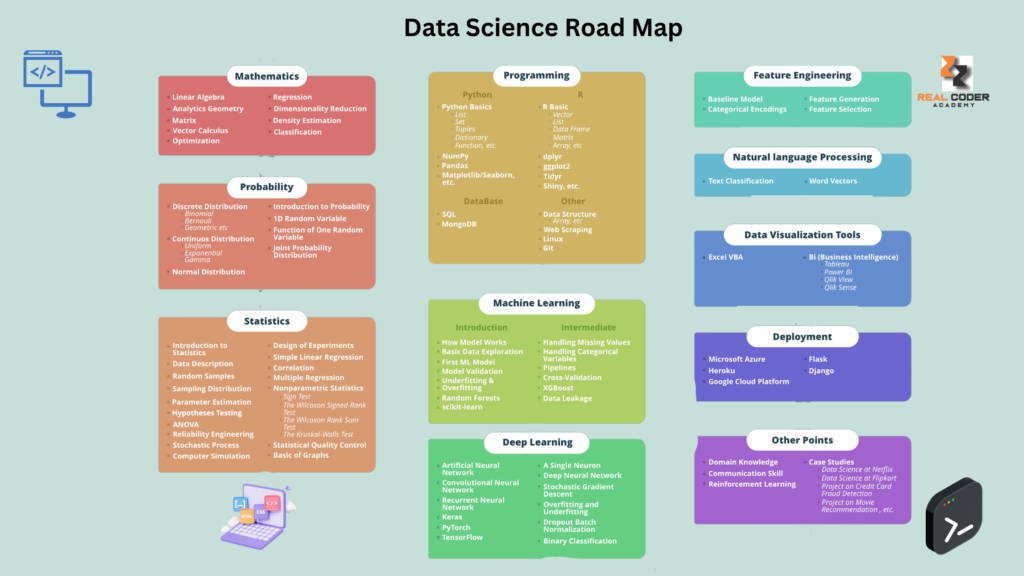
- Programming
- Python
- List
- Set
- Tuples
- Dictionary
- Function
- Numpy
- Pandas
- Matplotlib
- Seaborn
- Database
- SQL
- Postgres
- MySQL
- Oracle
- MongoDB
- SQL
- Machine Learning
- Linear regression
- Logic regression
- Nearest Neighbors
- Decision trees
- Random forest
- Support vector machine
- K Mean clustering
Key Tools and Library
Jupyter Notebook is an open-source web application that allows you to create and share documents containing live code, equations, visualizations, and explanatory text. Jupyter Notebooks are widely used for exploratory data analysis, data visualization, and sharing research findings. They are an essential tool for documenting your data science workflow.
Key Features
- Interactive coding environment.
- Integration with over 40 programming languages.
- Rich media support, including images, videos, and HTML.
Seaborn
Seaborn is a Python library built on Matplotlib designed to create attractive and informative statistical graphics.
Key Features
- Simplifies the creation of complex visualizations.
- Built-in themes and color palettes.
Plotly and Cufflinks
Plotly is a graphing library for interactive visualizations, and Cufflinks bridges Plotly with Pandas data frames.
Key Features
- Interactive charts and dashboards.
- Wide range of chart types, including 3D visualizations.
Linear and Logistic Regression
- Linear Regression: Predicts continuous outcomes.
- Logistic Regression: Predicts binary outcomes.
Practical Applications
- Predicting housing prices (Linear Regression).
- Classifying spam emails (Logistic Regression).
Nearest Neighbors and Decision Trees
- Nearest Neighbors: A simple, instance-based learning method.
- Decision Trees: A flowchart-like structure for decision-making.
Use Cases
- Nearest Neighbors: Recommender systems.
- Decision Trees: Credit risk assessment.
Natural Language Processing (NLP)
NLP is a subfield of AI focused on the interaction between computers and human language.
Key Features
- Text preprocessing (tokenization, stemming).
- Sentiment analysis and text generation.
Use Case
Sentiment analysis of customer reviews to improve products.
Neural Networks and Deep Learning
- Neural Networks: Computational models inspired by the human brain.
- Deep Learning: Advanced neural networks with multiple layers.
Use Cases
- Image recognition.
- Voice assistants.
Big Data and Spark
Big Data involves processing large volumes of data, and Apache Spark is a powerful engine for large-scale data processing.
Key Features
- Distributed data processing.
- Integration with Python via PySpark.
Data Manipulation: Pandas and NumPy
- Pandas is a library for data manipulation and analysis.
- NumPy is a library for numerical computations.
Learning resources
FreeCodeCamp is a fantastic free learning platform that offers interactive courses on various topics, including Python, data analysis, and machine learning. Their Data Science certification program provides hands-on projects that help learners develop real-world skills.
Coursera partners with top universities and organizations to offer high-quality courses and specializations in data science. Learners can access Stanford and the University of Michigan courses, making it an excellent choice for structured learning.
Udemy provides a vast library of courses at affordable prices, often with lifetime access. Many courses cover Python, machine learning, and deep learning, making it a flexible option for self-paced learning.
DataCamp is specifically designed for data science education, offering interactive coding exercises and real-world projects. It is an excellent platform for beginners who want to practice hands-on coding in Python and R.
edX, founded by Harvard and MIT, offers professional certificates and degree programs in data science. With courses from institutions like Harvard and Microsoft, it provides high-quality education for learners looking to build a strong foundation.
Conclusion
Python’s vast ecosystem of tools and libraries has solidified its position as a cornerstone of data science. From data visualization and machine learning to big data and deep learning, mastering these tools can open up endless possibilities for uncovering insights and driving innovation.
Whether building predictive models or analyzing text data, this road map provides a strong foundation for your data science journey. Now, it’s your turn to dive in, experiment, and make a difference in data science.
Leave A Reply